مفهوم هش کد
هش کد هر عنصر مختص به خودشه و فقط با عنصری که باهاش برابره یکسانه.
فرض کنید یک کتاب داریم و میخوایم موضوع به خصوصی از کتاب رو باز و مطالعه کنیم، برای پیدا کردن صفحه ی مربوط به موضوع مورد نظر میتونیم صفحات کتاب رو دونه دونه ورق بزنیم تا موضوع مورد نظر رو پیدا کنیم ، ولی این کار وقت گیره، برای پیدا کردن موضوع مورد نظر داخل کتاب بهترین کار مراجعه کردن به فهرست مطالب کتابه و از طریق فهرست مطالب کتاب میتونیم صفحه ی مربوط به موضوع مورد نظر رو پیدا کرده و بدون اینکه بخوایم صفحات کتاب رو دونه دونه ورق بزنیم مستقیم بریم سراغ صفحه ی مربوط به موضوع مورد نظر.
با استفاده از لیست، لیست پیوندی، صف، پشته و... برای پیدا کردن یک عنصر از تمام عناصر رو دونه دونه بررسی میکنیم تا به عنصر مورد نظر برسیم ولی تو هش کردن، هر عنصر یک آدرس منحصر به فرد داره که و با استفاده از آدرس عنصر، بدون اینکه برنامه وقتشو برای جستجوی تمام عناصر تلف کنه.
در زبان های برنامه نویسی هر عنصر یک کد ثابتی داره که بهش هش کد (hash code) میگیم، هش کد مثل اثر انگشت میمونه و هش کد (hash code) هر عنصر فقط با عنصر برابر با خودش یکسانه.
a := 24
b := 24
c := 52
(a = b) != c ∴ (a.hashcode = b.hashcode) != c.hashcode
از هش کد ها مثل فهرست مطالب کتاب که گفته شد برای پیدا کردن جایگاه عنصر در map استفاده می کنیم.
بررسی map
در map عناصر به صورت جفت کلید (key) و مقدار (value) نگهداری میشن.
map یک پیاده سازی در ساختار داده است که عناصر رو به صورت جفت کلید (key) و مقدار (value) (یک عنصر به عنوان کلید و یک عنصر به عنوان مقدار) داخل خودش نگهداری میکنه؛ در map کلید ها نمیتونن تکراری باشن ولی مقادیر میتونن تکراری باشن، هر key و value به صورت جفت داخل یک آرایه نگهداری میشه، با هش کد (hash code) ها میتونیم یک map پیاده سازی کنیم اگه با هش کد (hash code) ها یک map رو پیاده سازی کنیم بهش HashMap میگیم، به map دیکشنری (Dictionary) هم میگن.
به جفت key و value در مپ entry میگیم و برای نگهداریشون یک کلاس تعریف میکنیم.
class Entry{
K key
V value
function getKey(): K{
return key
}
function getValue(): V{
return value
}
function setValue(newValue: V): V{
oldValue := value
value := newValue
return oldValue
}
}
هر value کلید مختص به خودشو داره key ها در map نمیتونن تکراری باشن، برای پیدا کردن key و value مورد نظر از هش کد کلید استفاده میکنیم، در map زمانی که دو کلید یکی باشن و هش کد های یکسانی داشته باشن میگیم دو کلید باهم برابرن.
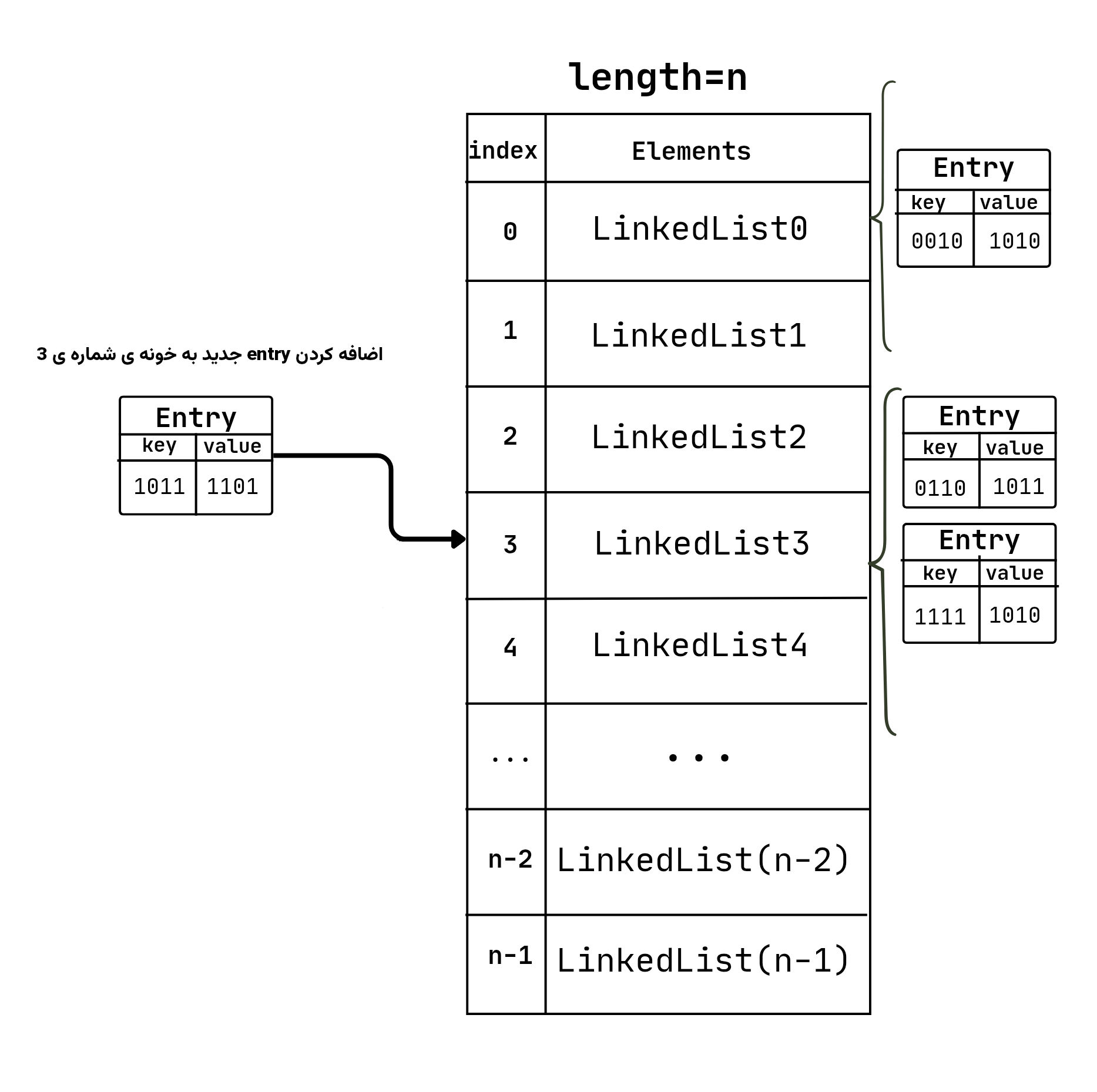
به آرایه ای که entry ها رو نگهداری می کنه buckets میگیم، bucket میتونه مستقیم entry ها رو نگهداری کنه یا یک آرایه باشه از linkedlist که هر linkedlist یک یا چند entry رو نگهداری می کنه.
برای پیدا کردن شماره خونه ی entry مورد نظر در map مانند زیر عمل می کنیم.
function hash(K key): int{
int h = key.hashcode
h = h ^ (h >>> 16)
return h & (buckets.length - 1)
}
در بالا با h ^ (h >>> 16) مطمئن میشیم هنگام گرفتن index از هش کد ها به تکرار کمتر می خوریم و همینطور با & فقط bit های مشترک بین هش کد و bucktes.length - 1 رو نگهداری می کنیم که نتیجش میشه یک عدد بین 0 تا buckets.length - 1 میتونستیم برای این کار بجای & از % استفاده کنیم اما سرعت محاسبه ی & بیشتره.
رفع تداخل index ها (collision resolution)
دو کلید مختلف، هش کد های مختلفی دارن ولی گاهی هنگام محاسبه ی index با تابع hash ممکنه index های دو کلید یکسان در بیاد، به این وضعیت تداخل (collision) میگیم.
برای رفع تداخل index ها میتونیم از زنجیره سازی مجزا (separate chaining) یا جستجو کردن خطی (linear probing) در پیاده سازی map استفاده کنیم.
زنجیره سازی مجزا (separate chaining)
در این روش یک آرایه از linkedlist ایجاد می کنیم و دو entry با index یکسان رو به linkedlist همون index اضافه می کنیم.
entries := new LinkedList[capacity]
جستجو کردن خطی (linear probing)
در این روش هر خونه ای در آرایه فقط یک entry رو نگهداری میکنه، زمانی که بخوایم یک entry رو به آرایه اضافه کنیم اگه index توسط یک entry دیگه پر شده باشه شروع به جستجو از index بعدی میکنیم تا یک خونه ی خالی در آرایه برای اضافه کردن entry جدید پیدا کنیم؛
entries := new Entry[capacity]
در زیر به صورت تصویری عملکرد روش linear probing بیان شده است.

رفع تداخل index ها (collision resolution) در روش separate chaining بهینه تره، در این مطلب به پیاده سازی map با روش separate chaining می پردازیم.
افزایش ظرفیت map
هنگامی که آرایه ی داخل map به یک حدی برسه باید ظرفیت آرایه افزایش پیدا کنه تا بتونیم عناصر جدید رو به map اضافه کنیم.
class MyHashMap{
loadFactor := 0.75
capacity := 16
size := 0
buckets := new LinkedList[capacity]
function resize(){
oldBuckets := buckets
mSize := 0
mCapacity := mCapacity * 2
buckets := new LinkedList[mSize]
for 0 <= i < oldBuckets.length
bucket := oldBuckets[i]
if bucket != null
for 0 <= j < bucket.size
put(bucket.key, bucket.value)
}
capacity طول آرایه ی تعریف شده در map رو نمایش می ده و size هم تعداد عناصر موجود در map رو نمایش میده.
با استفاده از loadFactor میتونیم آستانه ی افزایش ظرفیت آرایه رو مشخص کنیم، مقدار loadFactor باید بین 0 تا 1 باشه و آستانه ی ظرفیت برابر است با loadFactor * capacity زمانی که size مساوی یا بیشتر از این مقدار بشه capacity باید افزایش پیدا کنه.
توجه
در بالا برای loadFactor و capacity از مقادیر پیشفرض استفاده کردیم ولی در پیاده سازی واقعی میتونیم loadFactor و capacity رو داخل کانستراکتور مقداردهی کنیم.
صدا زدن مقدار با استفاده از کلید در map
با استفاده از key در map میتونیم یک value رو پیدا کنیم و value رو برگردونیم، پیچیدگی زمان برای پیدا کردن value برابر O(1) است.
function get(key: K): V{
index := hash(key)
bucket := buckets[index]
if bucket != null
for 0 <= i < bucket.size
entry := bucket.get(i)
if entry.key = key
return entry.value
return null
}
بررسی وجود کلید در map
اگه یک value وجود داشته باشه معلوم میشه کلید هم تو map وجود داره پیچیدگی زمان برای جستجوی key در map برابر صدا زدن value یعنی O(1) است.
function contains(key: K): boolean{
return get(key) != null
}
اضافه کردن جفت کلید و مقدار جدید به map
با استفاده از تابع put میتونیم یک جفت key و value رو به map اضافه کنیم، اگه key و value از قبل وجود داشتن مقدار value رو بروزرسانی می کنیم. پیچیدگی زمان این کار O(1) است.
برای اضافه کردن جفت key و value ابتدا بررسی می کنیم آیا کلید از قبل وجود داره یا خیر اگه کلید وجود داشت فقط مقدار value رو بروزرسانی می کنیم در غیر اینصورت بررسی میکنیم آیا به ظرفیت آرایه به استانه ی افزایش ظرفیت رسیده یا خیر اگه رسیده باشه برنامه با تابع resize که تعریف کردیم ظرفیت آرایه رو دو برابر می کنه و سپس key و value رو به عنوان مقادیر جدید به آرایه اضافه می کنه.
function put(key: K, value: V): V{
index := hash(key)
if index < 0
return null
if contains(key)
for 0<= i < buckets[index].size
entry := buckets[index].get(i)
if entry.key = key
return entry.setValue(value)
else
if size >= loadFactor * capacity
resize()
if buckets[index] = null
buckets[index] := new LinkedList()
buckets[index].add(new Entry(key, value))
size++
}
حذف جفت کلید و مقدار از map
برای حذف جفت key و value از map با کلید جستجو می کنیم اگه کلید و مقدار وجود داشتن، حذفشون می کنیم؛ پیچیدگی زمان برای حدف کردن جفت کلید و مقدار O(1) است.
function remove(key: K): V{
if contains(key)
index := hash(key)
bucket := buckets[index]
for 0<= i < bucket.size
if bucket.get(i).key = key
return bucket.remove(i)
size--
return null
}
پیاده سازی map در زبان های برنامه نویسی
در این قسمت میخوایم چیزایی که گفته شد رو به عنوان کلاس HashMap در زبان های برنامه نویسی (جاوا و کاتلین) به طور عملی پیاده کنیم.
import java.util.LinkedList;
public class MyHashMap<K, V> {
private static final int DEFAULT_CAPACITY = 16;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private int capacity;
private float loadFactor;
private int size = 0;
private LinkedList<Entry<K, V>>[] buckets;
public MyHashMap(int capacity, float loadFactor) {
if (loadFactor <= 0 || loadFactor > 1)
throw new IllegalArgumentException("load factor should be greater than 0 and less than or equal 1");
if (capacity <= 0) throw new IllegalArgumentException("Capacity can not be zero or less");
this.loadFactor = loadFactor;
this.capacity = capacity;
buckets = (LinkedList<Entry<K, V>>[]) new LinkedList[capacity];
}
public MyHashMap(int capacity) {
this(capacity, DEFAULT_LOAD_FACTOR);
}
public MyHashMap() {
this(DEFAULT_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public int hash(K key) {
if (key == null) return -1;
int h = key.hashCode();
h = h ^ (h >>> 16);
return h & (capacity - 1);
}
public V get(K key) {
int index = hash(key);
LinkedList<Entry<K, V>> bucket = buckets[index];
if (bucket != null) {
for (Entry<K, V> entry : bucket)
if (entry.getKey().equals(key))
return entry.getValue();
}
return null;
}
public boolean containsKey(K key) {
return get(key) != null;
}
public V put(K key, V value) {
int index = hash(key);
if (index < 0) return null;
if (size >= capacity * loadFactor) resize();
LinkedList<Entry<K, V>> bucket = buckets[index];
if (containsKey(key)) {
for (Entry<K, V> entry : bucket) {
if (entry.getKey().equals(key)) {
return entry.setValue(value);
}
}
} else {
if (bucket == null) buckets[index] = new LinkedList<>();
buckets[index].add(new Entry<>(key, value));
size++;
}
return value;
}
public V remove(K key) {
if (containsKey(key)){
int index = hash(key);
LinkedList<Entry<K, V>> bucket = buckets[index];
for (int i=0; i<bucket.size(); i++){
if (bucket.get(i).getKey().equals(key))
return bucket.remove(i).getValue();
}
size--;
}
return null;
}
public int getSize() {
return size;
}
@SuppressWarnings("unchecked")
private void resize() {
LinkedList<Entry<K, V>>[] oldBuckets = buckets;
size = 0;
capacity *= 2;
buckets = (LinkedList<Entry<K, V>>[]) new LinkedList[capacity];
for (LinkedList<Entry<K, V>> bucket : oldBuckets) {
if (bucket != null) {
for (Entry<K, V> entry : bucket) {
put(entry.getKey(), entry.getValue());
}
}
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("[ ");
for(LinkedList<Entry<K, V>> bucket : buckets){
if (bucket != null)
for (Entry<K, V> entry : bucket)
sb.append(entry).append(" ");
}
sb.append(" ]");
return sb.toString();
}
public static class Entry<K, V> {
private final K key;
private V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override
public String toString() {
return "{" + getKey() + " : " + getValue() + "}";
}
}
}
class MyHashMap<K, V> (var capacity: Int = DEFAULT_CAPACITY,val loadFactor: Float = DEFAULT_LOAD_FACTOR) {
var size: Int = 0
private set
private var buckets: Array<LinkedList<Entry<K?, V?>>?>
init {
require(!(loadFactor <= 0 || loadFactor > 1)) { "load factor should be greater than 0 and less than or equal 1" }
require(capacity > 0) { "Capacity can not be zero or less" }
buckets = arrayOfNulls(capacity)
}
fun hash(key: K?): Int {
if (key == null) return -1
var h = key.hashCode()
h = h xor (h ushr 16)
return h and (capacity - 1)
}
fun get(key: K?): V? {
val index = hash(key)
val bucket: LinkedList<Entry<K?, V?>>? = buckets[index]
if (bucket != null) {
for (entry in bucket) if (entry.key == key) return entry.value
}
return null
}
fun containsKey(key: K?): Boolean {
return get(key) != null
}
fun put(key: K?, value: V?): V? {
val index = hash(key)
if (index < 0) return null
if (size >= capacity * loadFactor) resize()
val bucket: LinkedList<Entry<K?, V?>>? = buckets[index]
if (containsKey(key)) {
for (entry in bucket!!) {
if (entry.key == key) {
return entry.setValue(value)
}
}
} else {
if (bucket == null) buckets[index] = LinkedList<Entry<K?, V?>>()
buckets[index]!!.add(Entry(key, value))
size++
}
return value
}
fun remove(key: K?): V? {
if (containsKey(key)) {
val index = hash(key)
val bucket: LinkedList<Entry<K?, V?>>? = buckets[index]
for (i in bucket!!.indices) {
if (bucket[i].key == key) return bucket.removeAt(i).value
}
size--
}
return null
}
private fun resize() {
val oldBuckets = buckets
size = 0
capacity *= 2
buckets = arrayOfNulls(capacity)
for (bucket in oldBuckets) {
if (bucket != null) {
for (entry in bucket) {
put(entry.key, entry.value)
}
}
}
}
override fun toString(): String {
val sb = StringBuilder()
sb.append("[ ")
for (bucket in buckets) {
if (bucket != null) for (entry in bucket) sb.append(entry).append(" ")
}
sb.append(" ]")
return sb.toString()
}
data class Entry<K, V>(val key: K?, var value: V?) {
fun setValue(value: V): V? {
val oldValue = this.value
this.value = value
return oldValue
}
override fun toString(): String {
return "{" + this.key + " : " + this.value + "}"
}
}
companion object {
private const val DEFAULT_CAPACITY = 16
private const val DEFAULT_LOAD_FACTOR = 0.75f
}
}
استفاده از map پیاده سازی شده
در زیر از Map پیاده سازی شده میخوایم استفاده کنیم.
MyHashMap<String, Integer> map = new MyHashMap();
map.put("Black", 0x000000);
map.put("White", 0xffffff);
map.put("Red", 0xff0000);
map.put("Green", 0x00ff00);
map.put("Blue", 0x0000ff);
System.out.println("hex code for color red to integer is :" + map.get("Red"));
System.out.println(map);
System.out.println("removing red from map the color in integer is:" + map.remove("Red"));
System.out.println("removing black from map the color value in integer is:" + map.remove("Black"));
System.out.println("Entries after removing red and black:");
System.out.println(map);
val map: MyHashMap<String, Int> = MyHashMap()
map.put("Black", 0x000000)
map.put("White", 0xffffff)
map.put("Red", 0xff0000)
map.put("Green", 0x00ff00)
map.put("Blue", 0x0000ff)
println("hex code for color red to integer is : ${map.get("Red")}")
println(map)
println("removing red from map the color in integer is: ${map.remove("Red")}")
println("removing black from map the color value in integer is: ${map.remove("Black")}")
println("Entries after removing red and black:")
println(map)
خلاصه
- هر عنصر هش کد مختص به خودشو داره و مقدارش با بقیه ی عناصر هم نوع خودش یکی نیست.
- یک map نگهدارنده ی آرایه ای از جفت کلید و مقدار است.
- به جفت کلید و مقدار entry میگیم و به آرایه ای که entry ها رو نگهداری میکنه bucket میگیم.
- از هش کد کلید (key) برای پیدا کردن index یک entry در map استفاده می کنیم.
- وقتی index دو کلید متفاوت با هم یکی شد میگیم دچار collision resolution شدیم.
- میتونیم با روش separate chaining یا linear probing مساله ی collision resolution رو حل کنیم.
- روش separate chaining بهینه تر از linear probing است.
- پیچیدگی زمان صدا زدن، اضافه کردن و حذف entry در map برابر با O(1) است.